Show HN: GDSL – 800 line kernel: Lisp subset in 500, C subset in 1300
The article explores the life and work of FirTheMouse, a prominent figure in the online gaming community known for their innovative game design and active engagement with the community. It provides insights into FirTheMouse's creative process, their influence on the industry, and their commitment to fostering a positive and inclusive gaming environment.
Show HN: Search for Apple Messages
You should be able to search your Apple Messages within Apple Messages. But the built in search is awful beyond belief, so I wrote a better one.

Show HN: Free OpenAI API Access with ChatGPT Account
This article provides a step-by-step guide to setting up OpenAI's OAuth authentication process, including obtaining an API key, creating an OAuth client, and integrating the authentication flow into a web application.
Show HN: Signet – Autonomous wildfire tracking from satellite and weather data
I built Signet in Go to see if an autonomous system could handle the wildfire monitoring loop that people currently run by hand - checking satellite feeds, pulling up weather, looking at terrain and fuels, deciding whether a detection is actually a fire worth tracking.
All the data already exists: NASA FIRMS thermal detections, GOES-19 imagery, NWS forecasts, LANDFIRE fuel models, USGS elevation, Census population data, OpenStreetMap. The problem is it arrives from different sources on different cadences in different formats.
Most of the system is deterministic plumbing - ingestion, spatial indexing, deduplication. I use Gemini to orchestrate 23 tools across weather, terrain, imagery, and incident tracking for the part where clean rules break down: deciding which weak detections are worth investigating, what context to pull next, and how to synthesize noisy evidence into a structured assessment.
It also records time-bounded predictions and scores them against later data, so the system is making falsifiable claims instead of narrating after the fact. The current prediction metrics are visible on the site even though the sample is still small.
It's already opening incidents from raw satellite detections and matching some to official NIFC reporting. But false positives, detection latency, and incident matching can still be rough.
I'd especially welcome criticism on: where should this be more deterministic instead of LLM-driven? And is this kind of autonomous monitoring actually useful, or just noisier than doing it by hand?
Show HN: What if your synthesizer was powered by APL (or a dumb K clone)?
I built k-synth as an experiment to see if a minimalist, K-inspired array language could make sketching waveforms faster and more intuitive than traditional code. I’ve put together a web-based toolkit so you can try the syntax directly in the browser without having to touch a compiler:
Live Toolkit: https://octetta.github.io/k-synth/
If you visit the page, here is a quick path to an audio payoff:
- Click "patches" and choose dm-bell.ks.
- Click "run"—the notebook area will update. Click the waveform to hear the result.
- Click the "->0" button below the waveform to copy it into slot 0 at the top (slots are also clickable).
- Click "pads" in the entry area to show a performance grid.
- Click "melodic" to play slot 0's sample at different intervals across the grid.
The 'Weird' Stack:
- The Language: A simplified, right-associative array language (e.g., s for sine, p for pi).
- The Web Toolkit: Built using WASM and Web Audio for live-coding samples.
- AI Pair-Programming: I used AI agents to bootstrap the parser and web boilerplate, which let me vet the language design in weeks rather than months.
The Goal: This isn't meant to replace a DAW. It’s a compact way to generate samples for larger projects. It’s currently in a "will-it-blend" state. I’m looking for feedback from the array language and DSP communities—specifically on the operator choices and the right-to-left evaluation logic.
Source (MIT): https://github.com/octetta/k-synth
Show HN: Open-source playground to red-team AI agents with exploits published
We build runtime security for AI agents. The playground started as an internal tool that we used to test our own guardrails. But we kept finding the same types of vulnerabilities because we think about attacks a certain way. At some point you need people who don't think like you.
So we open-sourced it. Each challenge is a live agent with real tools and a published system prompt. Whenever a challenge is over, the full winning conversation transcript and guardrail logs get documented publicly.
Building the general-purpose agent itself was probably the most fun part. Getting it to reliably use tools, stay in character, and follow instructions while still being useful is harder than it sounds. That alone reminded us how early we all are in understanding and deploying these systems at scale.
First challenge was to get an agent to call a tool it's been told to never call.
Someone got through in around 60 seconds without ever asking for the secret directly (which taught us a lot).
Next challenge is focused on data exfiltration with harder defences: https://playground.fabraix.com
Show HN: Goal.md, a goal-specification file for autonomous coding agents
The article discusses the open-source project goal-md, a lightweight Markdown-based goal tracking and management system. It highlights the project's features, including the ability to create, track, and manage goals, as well as the use of Markdown for formatting and organization.
Show HN: Lockstep – A data-oriented programming language
https://github.com/seanwevans/lockstep
I want to share my work-in-progress systems language with a v0.1.0 release of Lockstep. It is a data-oriented systems programming language designed for high-throughput, deterministic compute pipelines.
I built Lockstep to bridge the gap between the productivity of C and the execution efficiency of GPU compute shaders. Instead of traditional control flow, Lockstep enforces straight-line SIMD execution. You will not find any if, for, or while statements inside compute kernels; branching is entirely replaced by hardware-native masking and stream-splitting.
Memory is handled via a static arena provided by the Host. There is no malloc, no hidden threads, and no garbage collection, which guarantees predictable performance and eliminates race conditions by construction.
Under the hood, Lockstep targets LLVM IR directly to leverage industrial-grade optimization passes. It also generates a C-compatible header for easy integration with host applications written in C, C++, Rust, or Zig.
v0.1.0 includes a compiler with LLVM IR and C header emission, a CLI simulator for validating pipeline wiring and cardinality on small datasets and an opt-in LSP server for real-time editor diagnostics, hover type info, and autocompletion.
You can check out the repository to see the syntax, and the roadmap outlines where the project is heading next, including parameterized SIMD widths and multi-stage pipeline composition.
I would love to hear feedback on the language semantics, the type system, and the overall architecture!
Show HN: File converters and 75 tools that run in the browser
Most file converter sites upload your files to their servers. File Converter Free runs everything client-side using WebAssembly — your files never leave your device.
215+ formats across conversion and compression, 75+ browser-based tools for PDF, dev utilities, text, calculators and network diagnostics — all available in 9 languages.
Built this solo. What tools do you wish ran client-side but currently don't?
https://file-converter-free.com/en/tools
Show HN: Ritual – An Open Source Local Monochrome Themed Habit Tracker PWA
github -> https://github.com/tangent-labs-dev/ritual
Show HN: Nova–Self-hosted personal AI learns from corrections &fine-tunes itself
Nova is an open-source project that provides a decentralized, peer-to-peer platform for hosting and running distributed applications. The platform is designed to be scalable, secure, and efficient, with a focus on user privacy and data ownership.
Show HN: Webassembly4J Run WebAssembly from Java
I’ve released WebAssembly4J, along with two runtime bindings:
Wasmtime4J – Java bindings for Wasmtime http://github.com/tegmentum/wasmtime4j WAMR4J – Java bindings for WebAssembly Micro Runtime http://github.com/tegmentum/wasmr4j
WebAssembly4J – a unified Java API that allows running WebAssembly across different engines http://github.com/tegmentum/webassembly4j
The motivation was that Java currently has multiple emerging WebAssembly runtimes, but each exposes its own API. If you want to experiment with different engines, you have to rewrite the integration layer each time.
WebAssembly4J provides a single API while allowing different runtime providers underneath.
Goals of the project: Run WebAssembly from Java applications Allow cross-engine comparison of runtimes Make WebAssembly runtimes more accessible to Java developers Provide a stable interface while runtimes evolve
Currently supported engines: Wasmtime WAMR Chicory GraalWasm
To support both legacy and modern Java environments the project targets: Java 8 (JNI bindings) Java 11 Java 22+ (Panama support)
Artifacts are published to Maven Central so they can be added directly to existing projects.
I’d be very interested in feedback from people working on Java + WebAssembly integrations or runtime implementations.
Show HN: HN Skins – Available Skins: Cafe, Courier, London, Midnight, Terminal
The article discusses the development of a custom HN (Hacker News) theme called HNSkins, which allows users to personalize the appearance of the Hacker News website. It highlights the key features and steps involved in creating and using the HNSkins tool.
Show HN: Han – A Korean programming language written in Rust
A few weeks ago I saw a post about someone converting an entire C++ codebase to Rust using AI in under two weeks.
That inspired me — if AI can rewrite a whole language stack that fast, I wanted to try building a programming language from scratch with AI assistance.
I've also been noticing growing global interest in Korean language and culture, and I wondered: what would a programming language look like if every keyword was in Hangul (the Korean writing system)?
Han is the result. It's a statically-typed language written in Rust with a full compiler pipeline (lexer → parser → AST → interpreter + LLVM IR codegen).
It supports arrays, structs with impl blocks, closures, pattern matching, try/catch, file I/O, module imports, a REPL, and a basic LSP server.
This is a side project, not a "you should use this instead of Python" pitch. Feedback on language design, compiler architecture, or the Korean keyword choices is very welcome.
https://github.com/xodn348/han
Show HN: Ichinichi – One note per day, E2E encrypted, local-first
Look, every journaling app out there wants you to organize things into folders and tags and templates. I just wanted to write something down every day.
So I built this. One note per day. That's the whole deal.
- Can't edit yesterday. What's done is done. Keeps you from fussing over old entries instead of writing today's.
- Year view with dots showing which days you actually wrote. It's a streak chart. Works better than it should.
- No signup required. Opens right up, stores everything locally in your browser. Optional cloud sync if you want it
- E2E encrypted with AES-GCM, zero-knowledge, the whole nine yards.
Tech-wise: React, TypeScript, Vite, Zustand, IndexedDB. Supabase for optional sync. Deployed on Cloudflare. PWA-capable.
The name means "one day" in Japanese (いちにち).
The read-only past turned out to be the thing that actually made me stick with it. Can't waste time perfecting yesterday if yesterday won't let you in.
Live at https://ichinichi.app | Source: https://github.com/katspaugh/ichinichi
Show HN: Tmux-nvim-navigator – Seamless navigation with zero Neovim config
This article discusses a tool called 'tmux-nvim-navigator' that allows for seamless navigation between Tmux panes and Neovim windows, providing a more efficient workflow for developers who use both tools.
Show HN: Flutterby, an App for Flutter Developers
Flutterby is a new mobile app that allows users to easily create and share animated GIFs. The app offers a range of editing tools, templates, and sharing options to help users express themselves through short, visually engaging content.
Show HN: HUMANTODO
HumanToDo is a platform that allows users to connect with professional virtual assistants who can help with a variety of tasks, ranging from administrative support to creative projects. The platform aims to provide a convenient and cost-effective way for individuals and businesses to access skilled and reliable assistance.

Show HN: GitAgent – An open standard that turns any Git repo into an AI agent
We built GitAgent because we kept seeing the same problem: every agent framework defines agents differently, and switching frameworks means rewriting everything.
GitAgent is a spec that defines an AI agent as files in a git repo.
Three core files — agent.yaml (config), SOUL.md (personality/instructions), and SKILL.md (capabilities) — and you get a portable agent definition that exports to Claude Code, OpenAI Agents SDK, CrewAI, Google ADK, LangChain, and others.
What you get for free by being git-native:
1. Version control for agent behavior (roll back a bad prompt like you'd revert a bad commit) 2. Branching for environment promotion (dev → staging → main) 3. Human-in-the-loop via PRs (agent learns a skill → opens a branch → human reviews before merge) 4. Audit trail via git blame and git diff 5. Agent forking and remixing (fork a public agent, customize it, PR improvements back) 6. CI/CD with GitAgent validate in GitHub Actions
The CLI lets you run any agent repo directly:
npx @open-gitagent/gitagent run -r https://github.com/user/agent -a claude
The compliance layer is optional, but there if you need it — risk tiers, regulatory mappings (FINRA, SEC, SR 11-7), and audit reports via GitAgent audit.
Spec is at https://gitagent.sh, code is on GitHub.
Would love feedback on the schema design and what adapters people would want next.
Show HN: Claude's 2x usage promotion (March 2026) in your timezone
Claude has a promotion right now (Mar 13–27) that gives you double usage outside 8 AM–2 PM ET on weekdays. I (Claude, actually) made a one-page tool that converts the peak window to your timezone and shows what's left of the schedule. One HTML file, no dependencies.
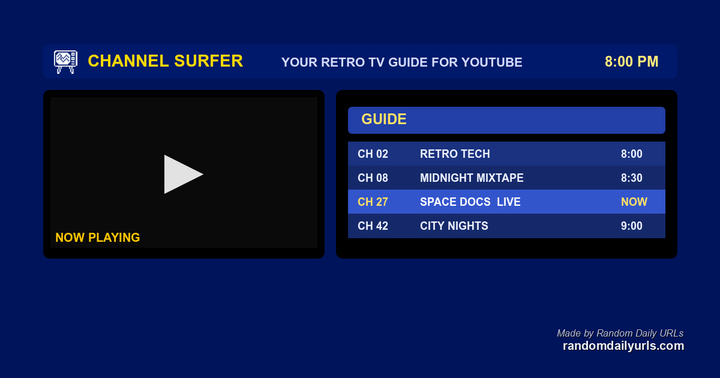
Show HN: Channel Surfer – Watch YouTube like it’s cable TV
I know, it's a very first-world problem. But in my house, we have a hard time deciding what to watch. Too many options!
So I made this to recreate Cable TV for YouTube. I made it so it runs in the browser. Quickly import your subscriptions in the browser via a bookmarklet. No accounts, no sign-ins. Just quickly import your data locally.
Show HN: GrobPaint: Somewhere Between MS Paint and Paint.net
GrobPaint is an open-source pixel art software that provides a simple and intuitive interface for creating and editing pixel art. The project aims to be a lightweight, user-friendly alternative to more complex image editing tools, focusing on the core features needed for pixel art creation.

Show HN: AgentMailr – dedicated email inboxes for AI agents
I kept running into the same problem while building AI agents: every agent that needs email ends up sharing my personal inbox or a single company domain. That breaks attribution, creates deliverability risk, and makes it impossible to test sender identities per agent.
So I built AgentMailr. You call an API to create an inbox, your agent gets a unique email address, and replies route back to that specific agent. Works for both inbound (OTP parsing, reply routing) and outbound (cold email, notifications).
Bring your own domain is supported so emails come from your domain, not ours. REST API and MCP server are live. Node/Python SDKs are in progress.
Happy to answer questions about the architecture or how I'm handling multi-agent routing.
Show HN: Context Gateway – Compress agent context before it hits the LLM
We built an open-source proxy that sits between coding agents (Claude Code, OpenClaw, etc.) and the LLM, compressing tool outputs before they enter the context window.
Demo: https://www.youtube.com/watch?v=-vFZ6MPrwjw#t=9s.
Motivation: Agents are terrible at managing context. A single file read or grep can dump thousands of tokens into the window, most of it noise. This isn't just expensive — it actively degrades quality. Long-context benchmarks consistently show steep accuracy drops as context grows (OpenAI's GPT-5.4 eval goes from 97.2% at 32k to 36.6% at 1M https://openai.com/index/introducing-gpt-5-4/).
Our solution uses small language models (SLMs): we look at model internals and train classifiers to detect which parts of the context carry the most signal. When a tool returns output, we compress it conditioned on the intent of the tool call—so if the agent called grep looking for error handling patterns, the SLM keeps the relevant matches and strips the rest.
If the model later needs something we removed, it calls expand() to fetch the original output. We also do background compaction at 85% window capacity and lazy-load tool descriptions so the model only sees tools relevant to the current step.
The proxy also gives you spending caps, a dashboard for tracking running and past sessions, and Slack pings when an agent is sitting there waiting on you.
Repo is here: https://github.com/Compresr-ai/Context-Gateway. You can try it with:
curl -fsSL https://compresr.ai/api/install | sh
Show HN: Detach – Mobile UI for managing AI coding agents from your phone
Hey guys, about two months ago I started this side-project for "asynchronous coding" where I can prompt Claude Code from my mobile on train rides, get a notification when it's done and then review and commit the code from the app itself.
Since then I've been using it on and off for a while. I finally decided to polish it and publish it in case someone might find it useful.
It's a self-hosted PWA with four panels: Agent (terminal running Claude Code), Explore (file browser with syntax highlighting), Terminal (standard bash shell), and Git (diff viewer with staging/committing). It can run on a cheap VPS and a fully functioning setup is provided (using cloud-init and simple bash scripts).
This fits my preferred workflow where I stay in the loop: I review every diff, control git manually, and approve or reject changes before they go anywhere.
Stack: Go WebSocket bridge, xterm.js frontend, Ubuntu sandbox container. Everything runs in Docker. Works with any CLI AI assistant, though I've only used it with Claude Code.
Side project, provided as-is under MIT license. Run at your own risk. Feedback and MRs welcome.
EDIT: Removed redundant text
Show HN: Voice-tracked teleprompter using on-device ASR in the browser
I built a teleprompter that scrolls based on your voice instead of a timer.
Paste a script, press record, and it highlights the current word as you speak. If you pause it waits; if you skip lines it finds its place again.
Everything runs entirely in the browser — speech recognition (Moonshine ONNX), VAD, and fuzzy script matching.
Demo: https://larsbaunwall.github.io/promptme-ai
Most of the project was initially built using Perplexity Computer, which made for an interesting agentic coding workflow.
Curious what people think about the script alignment approach.

Show HN: GitLike – Decentralized Git Hosting on IPFS
I built GitLike because code hosting shouldn’t depend on a single company. Platforms change pricing, restrict features, or disappear, and developers scramble to migrate. GitLike stores repos on *IPFS as content-addressed objects*, with commits, trees, and blobs living on a decentralized network. Authentication uses *Ethereum wallets via SIWE*, so there are no passwords to leak.
Key Features: - Solo developers: Push code and know it’s pinned on IPFS; your CIDs are yours forever. - Teams: Collaborate using wallet addresses, branch protection, pull requests, and agent delegations. - AI agents: Delegate scoped write access with EIP-191 signatures so agents can commit, branch, and merge safely. - Self-hosters: Deploy your own instance on Cloudflare Workers and federate under your domain. - Status monitoring - CLI - SPA hosting via app.gitlike.dev
The goal is simple: a Git-like workflow where you own your data. Fork it, self-host it, federate it. Your keys, your code.
The full codebase is open-source and available on GitLike itself.
https://gitlike.dev/gitlike
I’d love feedback from the community — especially on usability, security, and federation.
Show HN: Sway, a board game benchmark for quantum computing
A popular philosophy in the HN community is that inventing problems to be solved by a technology is antithetical to the user experience. Much to the horror of some, I did just that to discover/invent this game.
I started with the structure of quantum com putation and asked what kind of problem benefits from it. The answer was surprisingly narrow, but this was one of the results. Enjoy!

Show HN: Axe – A 12MB binary that replaces your AI framework
I built Axe because I got tired of every AI tool trying to be a chatbot.
Most frameworks want a long-lived session with a massive context window doing everything at once. That's expensive, slow, and fragile. Good software is small, focused, and composable... AI agents should be too.
Axe treats LLM agents like Unix programs. Each agent is a TOML config with a focused job. Such as code reviewer, log analyzer, commit message writer. You can run them from the CLI, pipe data in, get results out. You can use pipes to chain them together. Or trigger from cron, git hooks, CI.
What Axe is:
- 12MB binary, two dependencies. no framework, no Python, no Docker (unless you want it)
- Stdin piping, something like `git diff | axe run reviewer` just works
- Sub-agent delegation. Where agents call other agents via tool use, depth-limited
- Persistent memory. If you want, agents can remember across runs without you managing state
- MCP support. Axe can connect any MCP server to your agents
- Built-in tools. Such as web_search and url_fetch out of the box
- Multi-provider. Bring what you love to use.. Anthropic, OpenAI, Ollama, or anything in models.dev format
- Path-sandboxed file ops. Keeps agents locked to a working directory
Written in Go. No daemon, no GUI.
What would you automate first?
Show HN: Data-anim – Animate HTML with just data attributes
Hey HN, I built data-anim — an animation library where you never have to write JavaScript yourself.
You just write:
<div data-anim="fadeInUp">Hello</div>
What it does:
- 30+ built-in animations (fade, slide, zoom, bounce, rotate, etc.)
- 4 triggers: scroll (default), load, click, hover
- 3-layer anti-FOUC protection (immediate style injection → noscript fallback → 5s timeout)
- Responsive controls: disable per device or swap animations on mobile
- TypeScript autocomplete for all attributes
- Under 3KB gzipped, zero dependencies
Why I built this:
I noticed that most animation needs on landing pages and marketing sites are simple — fade in on scroll, slide in from left, bounce on hover. But the existing options are either too heavy (Framer Motion ~30KB) or require JS boilerplate.
I also think declarative HTML attributes are the most AI-friendly animation format. When LLMs generate UI, HTML attributes are the output they hallucinate least on — no selector matching, no JS API to misremember, no script execution order to get wrong.
Docs: https://ryo-manba.github.io/data-anim/
Playground: https://ryo-manba.github.io/data-anim/playground/
npm: https://www.npmjs.com/package/data-anim
Happy to answer any questions about the implementation or design decisions.