Polymarket gamblers threaten to kill me over Iran missile story
The article reports on threats received by a journalist from gamblers who are unhappy with a story he wrote about Iran's missile program. The gamblers are allegedly trying to coerce the journalist into rewriting the story in order to influence the outcome of a bet placed on the online platform Polymarket.

Palestinian boy, 12, describes how Israeli forces killed his family in car
The article discusses the potential risks and benefits of artificial intelligence (AI) as the technology becomes more advanced and prevalent in various industries. It explores concerns about AI's impact on jobs and the need for responsible development and regulation of the technology.

Bill C-22, the Lawful Access Act: Dangerous backdoor surveillance risks remain
https://www.parl.ca/DocumentViewer/en/45-1/bill/C-22/first-r...
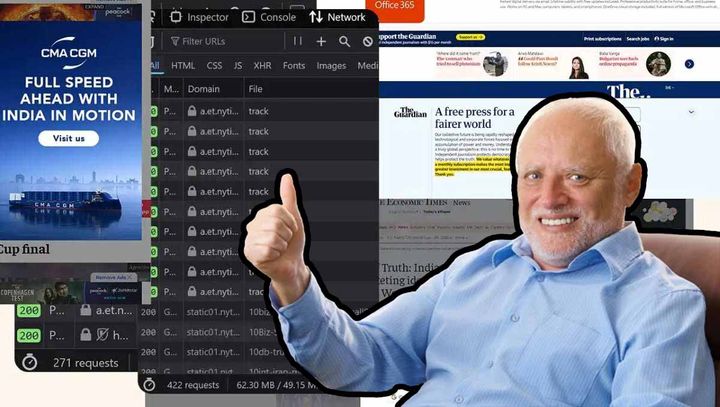
The 49MB web page
The article discusses the importance of auditing news sources to verify their credibility and accuracy. It emphasizes the need for readers to critically evaluate the information they consume and encourages them to cross-check facts from multiple reliable sources.

Corruption erodes social trust more in democracies than in autocracies
Stop Sloppypasta

MoD sources warn Palantir role at heart of government is threat to UK security
The article explores Palantir Technologies' contract with the UK Ministry of Defense to provide data insights and analysis, raising concerns about the company's access to sensitive government data and its role in the security state.

Chrome DevTools MCP (2025)
The article discusses the new Multi-Client Debugging feature in Chrome DevTools, which allows developers to debug their browser sessions across multiple devices and browsers simultaneously, providing a more comprehensive debugging experience.
US SEC preparing to scrap quarterly reporting requirement
The U.S. Securities and Exchange Commission (SEC) is preparing to eliminate the requirement for publicly traded companies to report quarterly, according to the Wall Street Journal. The move is aimed at reducing the regulatory burden on businesses and encouraging a longer-term focus in the markets.
LLM Architecture Gallery
The article presents an in-depth visual gallery showcasing the architectural designs and components of various large language models, highlighting the diversity of approaches and techniques employed by researchers and engineers in the field of natural language processing.

Leanstral: Open-source agent for trustworthy coding and formal proof engineering
Lean 4 paper (2021): https://dl.acm.org/doi/10.1007/978-3-030-79876-5_37

How I write software with LLMs
The article discusses the author's approach to writing software using large language models (LLMs), highlighting the benefits of leveraging these models for tasks such as code generation, documentation, and problem-solving, while also addressing potential challenges and considerations when integrating LLMs into software development workflows.
Kagi Translate now supports LinkedIn Speak as an output language
The article discusses the use of 'LinkedIn speak' - the unique vocabulary and phrasing often found on the professional networking platform. It examines how this language style has become a norm, and how understanding it can help users communicate more effectively on LinkedIn.
US Job Market Visualizer
The article discusses Andrej Karpathy's journey from a PhD student to leading the AI team at Tesla. It highlights his background, his work at OpenAI and Tesla, and his perspectives on the future of AI and the tech industry.

Meta’s renewed commitment to jemalloc
https://github.com/jemalloc/jemalloc
Why I love FreeBSD
The article discusses the author's love for the FreeBSD operating system, highlighting its stability, security, and flexibility as key reasons for their preference over other options.
$96 3D-printed rocket that recalculates its mid-air trajectory using a $5 sensor
This article describes the development of a MANPADS (Man-Portable Air Defense System) System Launcher and Rocket, a critical component for defending against airborne threats. The project aims to create a reliable and effective system to protect against various aerial targets.
The “small web” is bigger than you might think
The article discusses the trend of 'small web' websites, which are simple, fast, and focused on content rather than features. It argues that this approach can be more effective and sustainable than the complex, feature-rich websites that have become the norm.

Nasdaq's Shame
The article examines the Nasdaq stock exchange's role in the proliferation of special purpose acquisition companies (SPACs), highlighting concerns about the lack of transparency and increased risk for investors in these deals.
Ask HN: How is AI-assisted coding going for you professionally?
Comment sections on AI threads tend to split into "we're all cooked" and "AI is useless." I'd like to cut through the noise and learn what's actually working and what isn't, from concrete experience.
If you've recently used AI tools for professional coding work, tell us about it.
What tools did you use? What worked well and why? What challenges did you hit, and how (if at all) did you solve them?
Please share enough context (stack, project type, team size, experience level) for others to learn from your experience.
The goal is to build a grounded picture of where AI-assisted development actually stands in March 2026, without the hot air.

A Visual Introduction to Machine Learning (2015)
This article provides a visual introduction to machine learning, explaining the core concepts of supervised learning, training data, and model predictions. It uses a simple example of predicting house prices to illustrate these fundamental machine learning principles.
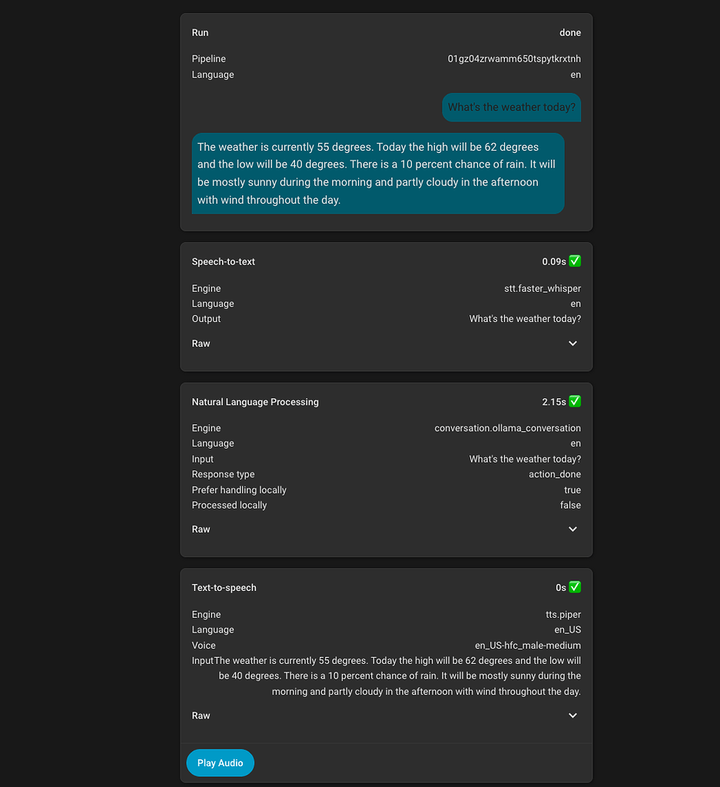
My Journey to a reliable and enjoyable locally hosted voice assistant (2025)
The article outlines the author's journey to create a reliable and enjoyable locally-hosted voice assistant, highlighting the challenges faced and the solutions implemented to achieve a seamless and secure home automation experience.
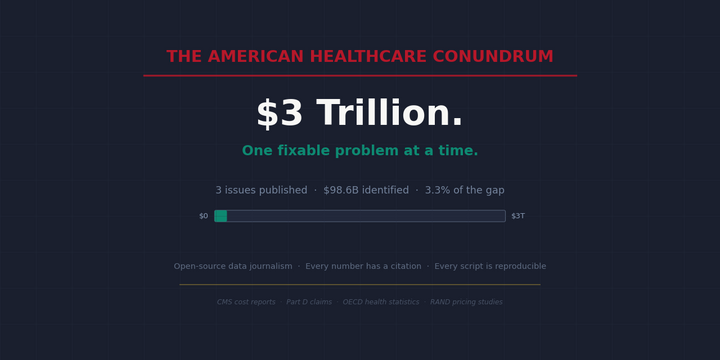
The American Healthcare Conundrum
The article explores the complexities and challenges of the American healthcare system, examining its high costs, limited accessibility, and ongoing debates surrounding potential reforms to address these issues.

LLMs can be exhausting
The article discusses the challenges and exhaustion that can come with using large language models (LLMs), highlighting the cognitive load, time investment, and frustration experienced by the author when attempting to leverage these AI systems for various tasks.
Separating the Wayland compositor and window manager
This article discusses 'River Window Management', a window management technique that allows users to easily organize and navigate multiple windows on their computer desktop. It explains the key features and benefits of this approach, such as improved productivity and visual clarity.
Office.eu launches as Europe's sovereign office platform

Glassworm is back: A new wave of invisible Unicode attacks hits repositories
The article discusses a security vulnerability, known as the 'Glassworm' attack, that targets Unicode characters in software packages like GitHub, npm, and Visual Studio Code. The vulnerability allows attackers to execute arbitrary code by exploiting how these platforms handle certain Unicode characters.

AirPods Max 2
The article discusses Apple's new AirPods Max, a premium over-the-ear headphone offering advanced features like active noise cancellation, spatial audio, and a stainless steel design, targeted at high-end audio enthusiasts.

Obsession with growth is destroying nature, 150 countries warn
The article reports that over 150 countries have warned that the world's obsession with economic growth is destroying nature and biodiversity. It highlights the call from these countries for a shift towards sustainable development that balances economic, social, and environmental considerations.
